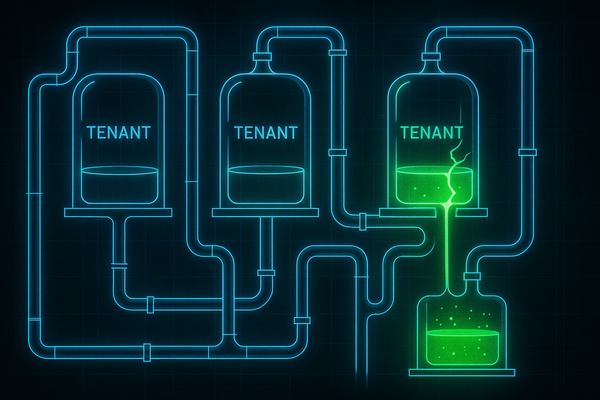
There is a particular kind of engineering regret that only arrives after you have done something well. Not the regret of shipping something broken, or cutting corners under deadline pressure. This is the quieter, more unsettling kind: the regret of spending months building something elegant, robust, and technically impressive, only